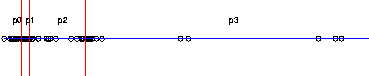

| Title | Adaptive Parallel Multigrid Methods with Space-Filling Curves and Hash Storage | |||||||||||||||
| Participant | Gerhard Zumbusch | |||||||||||||||
| Key words | Additive Multigrid, Multi-Level Methods, BPX-Preconditioner, Adaptive Grid Refinement, A Posteriori Error Estimators, Dynamic Load-Balancing, Distributed Memory, Message Passing, Space-Filling Curves, Key Based Addressing, Hash Storage | |||||||||||||||
| Description |
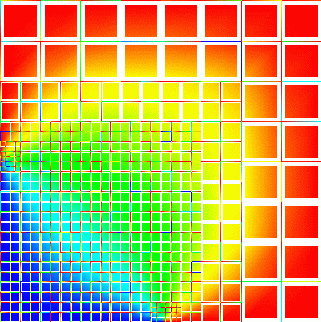
Problem:We are interested in the solution of boundary value problems of partial differential equations. As a prototype we choose the Poisson equation. Two typical solutions on adapted grids, computed with a finite difference discretization looks like this:
We want to construct an efficient solver, which uses an optimal order solution algorithm (multigrid), a low number of unknowns (adaptivity), very little memory (hash storage) and runs on large parallel computers. Especially the grid adaptivity poses some difficulties for the parallel implementation. Multigrid:Multigrid and multilevel methods are optimal order solution algorithms
for equation systems stemming from the discretization of PDEs. They require
linear time, that is O(n) operations for n unknowns. A basic
scheme is the additive multigrid preconditioner BPX defined as
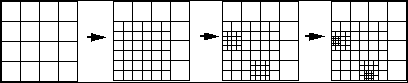
Adaptive Grids:In the presence of sigularities of the solution the convergence of standard discretizations is not as rapid as for smooth, regular solutions. One way to overcome this problem is adaptivity. The grid is refined during the computation where indicated by an error estimator or error indicator:
We enforce 1-irregular grids, that is each edge contains at least one hanging node, which is incorporated into the finite difference discretization.
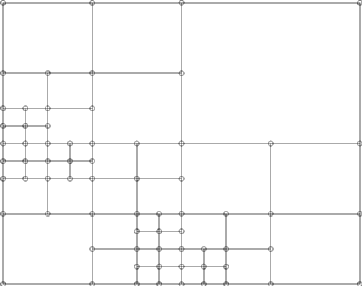
Load Balancing:The parallelization of adaptively refined grids in one dimension is simple. Consider a refined grid, the domain is partitioned into intervals of equal workload. Each processor holds the same number of nodes:
The partition can be stored by (p-1) separators (numbers) for p processors. Let us look at the higher dimensional case
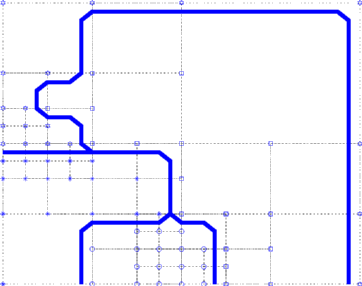
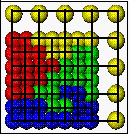
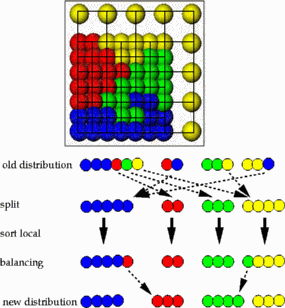
We can map the domain to the interval by a space-filling curve. This mapping induces an order of the nodes and elements. We can proceed like in the one dimensional case using (p-1) separators
which results in the following domain decomposition.
Note that each processor is assigned the same work load (number of nodes), but thesubdomain boundaries are sub-optimal. Solving both the partition problem and minmizing the boundaries, which are a measure of communication cost during the parallel computation, is an NP-hard problem.
The main advantages of this partition method are:
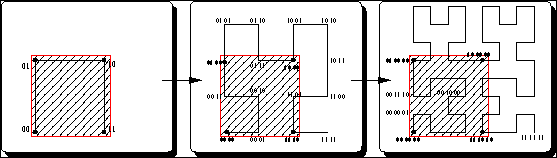
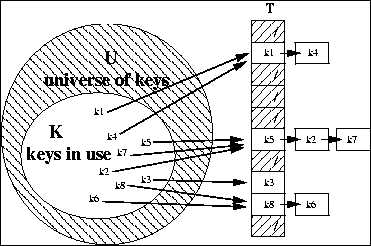
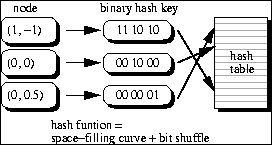
Key based implementation:We need to store a hierarchicaly nested sequence of adapted grids which includes nodes (= degrees of freedom) and their geometric relationship on the grid and their relation to nodes on different grid levels. In contrast to standard data structures based on pointers and trees, we choose a key based addressing scheme and hash storage. A hash table T contains all nodes (on a processor).
Each node can be accessed via its coordinates, which is coded uniquely in its position on the space-filling curve. This unique key is mapped to the hash table via a surjective hash function. Collsions are resolved with chaining in the C++ STL implementation in use.
This results in a statistical constant time access O(1) and a substancial saving in computer memory. An even greater improvement comes from the fact that we do not have to administer pointers, which causes trouble on distributed memory parallel computers, where one has to create and maintain copies of lots of entities otherwise.
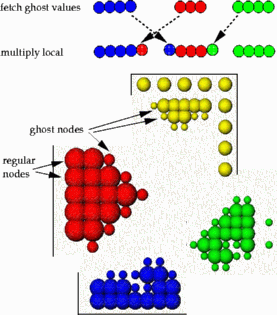
Parallelization:The components of our adaptive multigrid code have to be parallelized. A single data decomposition is used on the distributed memory computer. However, each component requires a different reatment.
For the iterative solution of the equation system we need matrix multiplies Ax. The ghost nodes are located on the processor boundaries (processors 1-4).
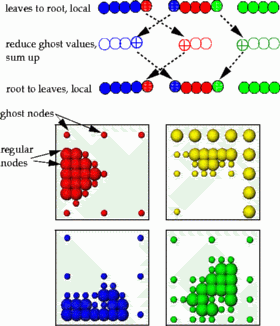
The multigrid BPX type preconditioner uses ghost nodes which are located on hierarchical neighbours of processor boundaries. The implementation requires two communication steps independent of the number of grid levels.
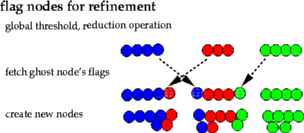
While error estimation is similar to the solution of the equation system, the refinement algorithm looks different:
The load balancing based on space-filling curves can be implemented as a one stage parallel sort (radix or bucket sort) based on the previous partition. This results in a well balanced parallel sorting itself and a low number and volume of data transfers.
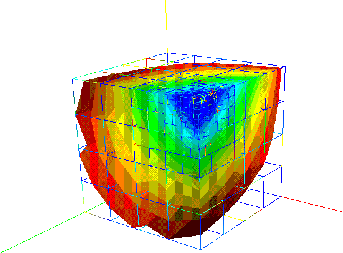
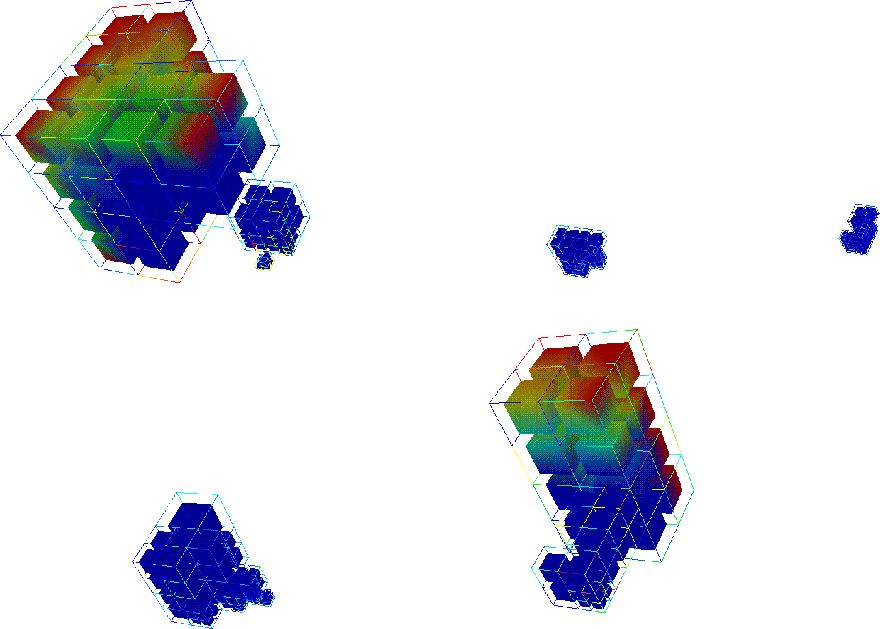
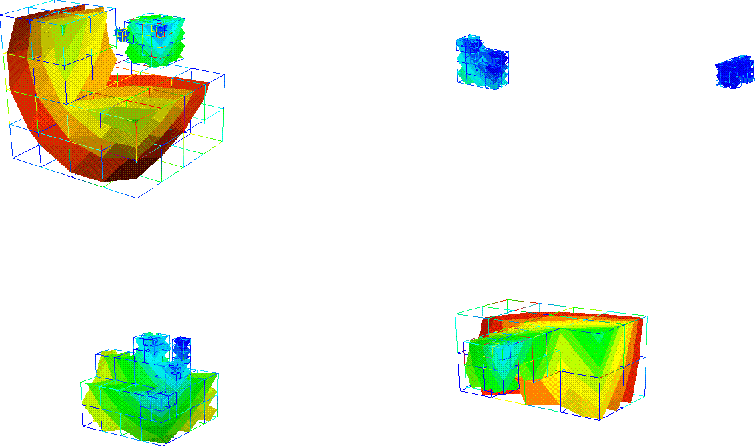
Results:Here are some three dimensional results
and the partition
The iso-lines of the solution
partitioned onto the processors
|
|||||||||||||||
| Bibliography |
|
|||||||||||||||
| Related projects |
|
|||||||||||||||
| In cooperation with | SFB 256 "Nonlinear Partial Differential Equations" | |||||||||||||||