
However, many algorithms assume that the data is given and stored on a regular grid. Although this allows simple data structures and implicit traversal of the hierarchy, the benefits from reduced triangle counts do not carry over to the memory consumption. On the other side, storing the approximations as irregular triangle meshes leads to high memory requirements per triangle (or vertex) for a multiresolution mesh and is thus inefficient for small approximation errors.
We developed a compression scheme based on space-filling curves and relative branch pointers which allows an efficient storage of large digital elavation models with full multiresolution functionality. Most importantly, this allows a working on the compressed data itself. The total memory requirement of the data structures is less than 7 bytes per vertex independent of the maximum level of the hierarchy. The latter property is very important for very large scale or compound models consisting of several layers of terrain data.
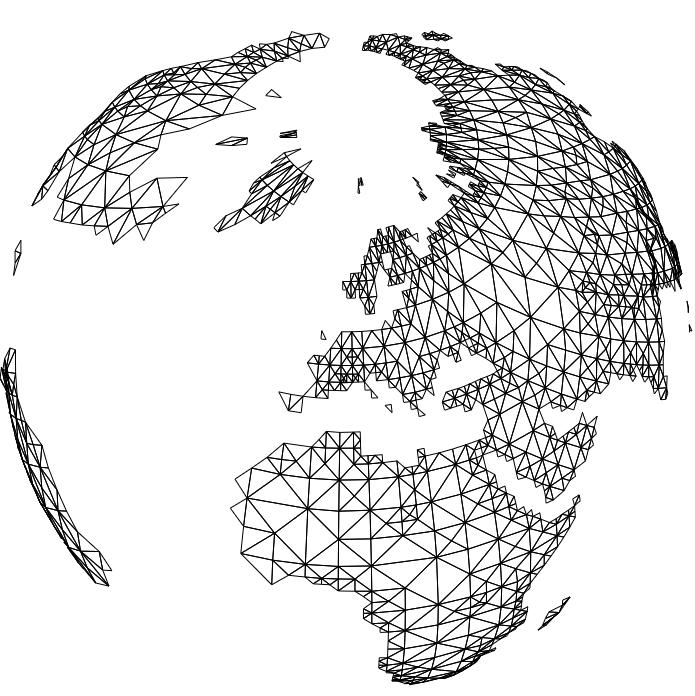
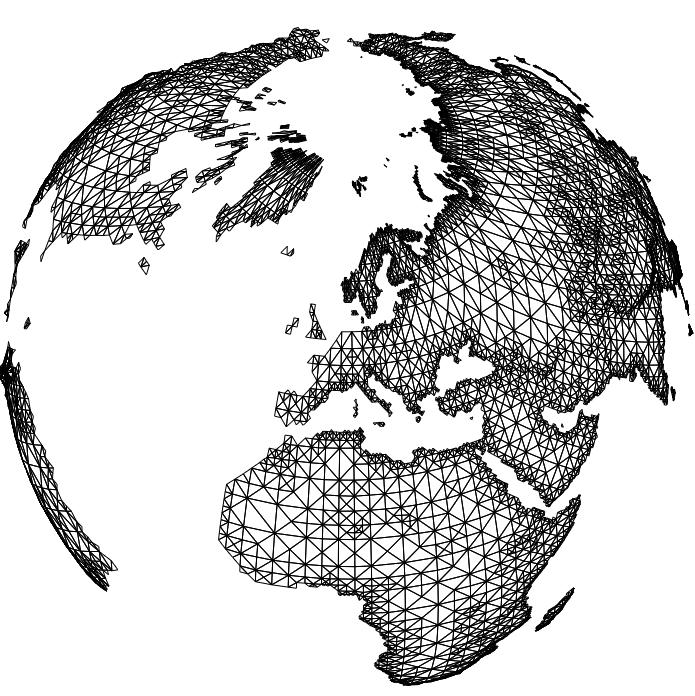


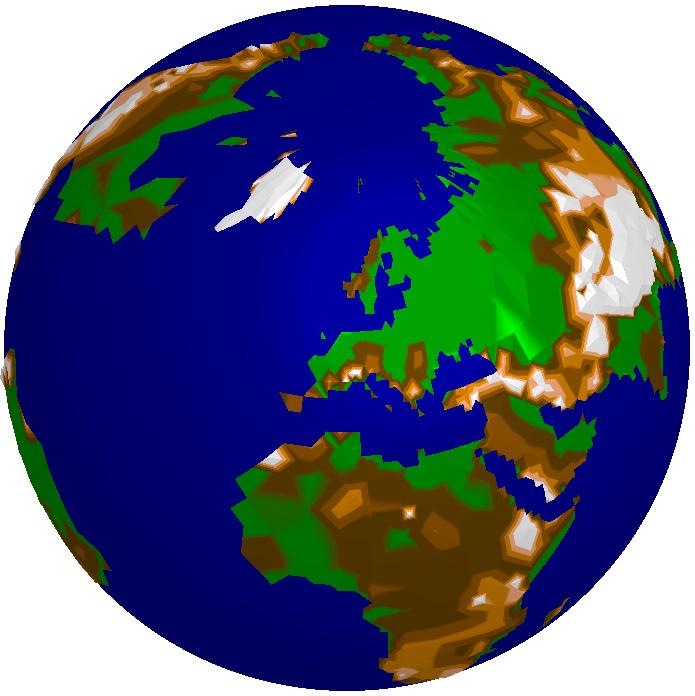
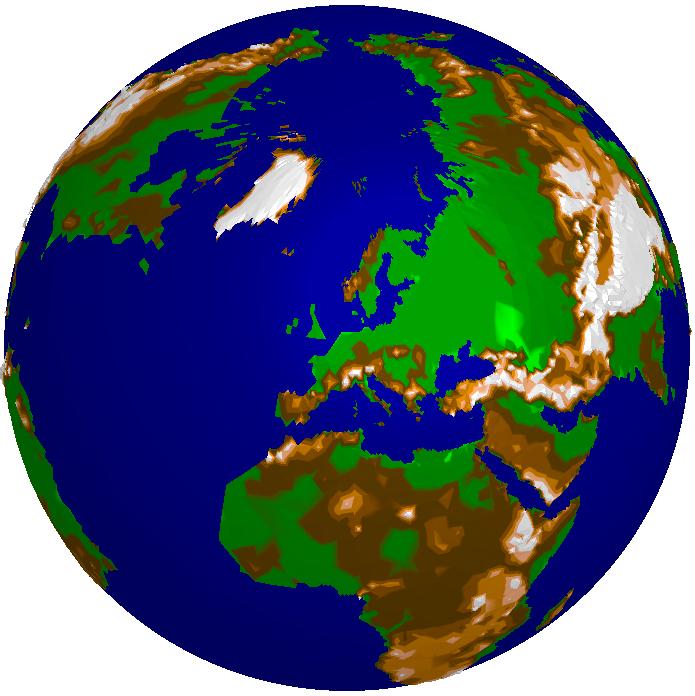
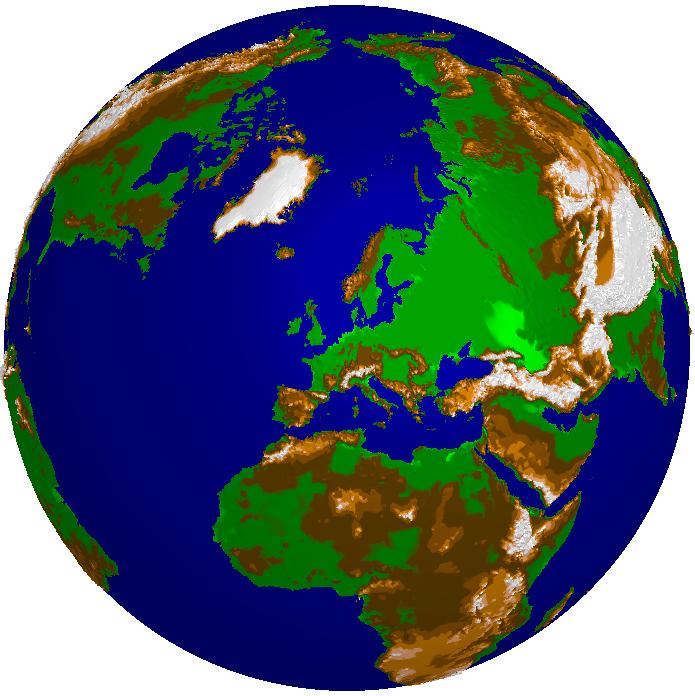
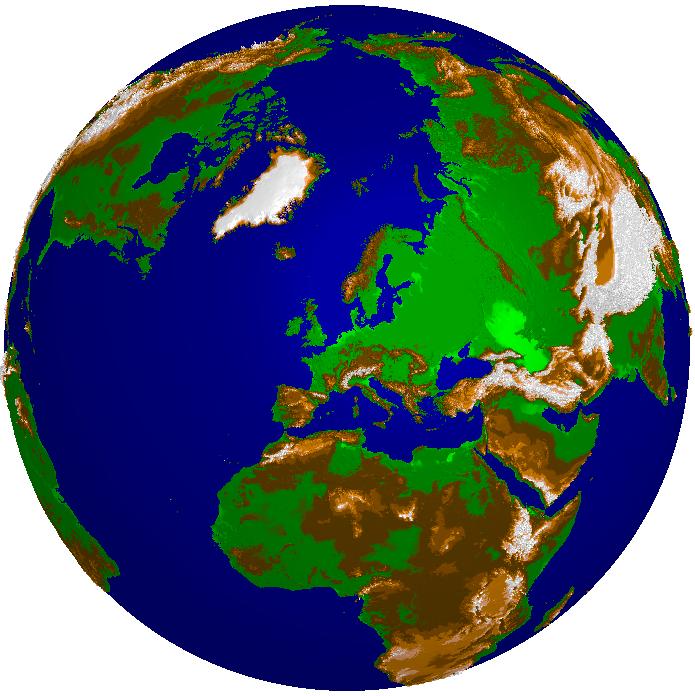
Here you see the global gtopo30 dataset (courtesy of USGS) in several approximations with decreasing approximation error from left to right. The storage requirement ranges from a several KBytes for 3000 triangles (left image) to a few MBytes for one million triangles (right image). The relative error of the rightmost image is about 3.6%. In contrast, the original size of the data set would be several hundred MBytes. In the lower row you see the color shaded DEM, in the upper row the corresponding adaptive grids.




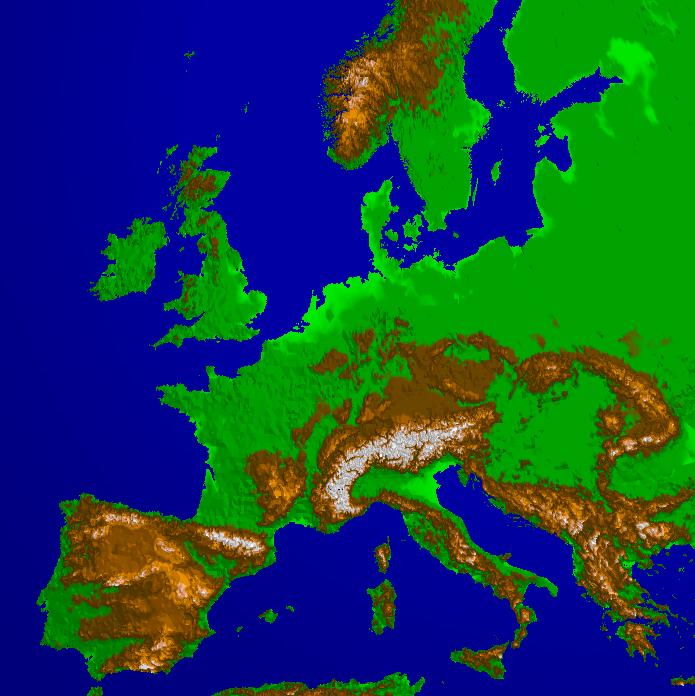
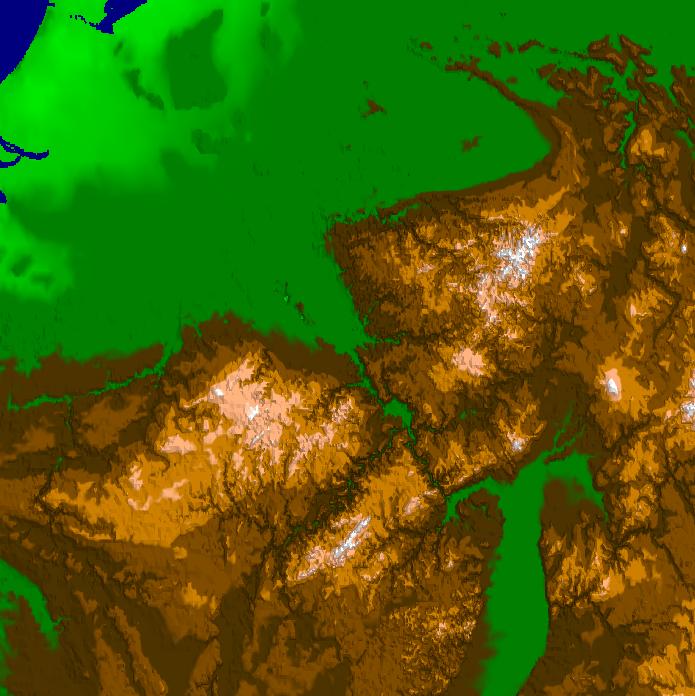


In order to show the real benefits of the method we added two further data sets to the global model. One data set covers the lower Rhine valley (courtesy of SFB350) with a resolution of 50m which is nested in the global data set. The second data set covers the city of Bonn (courtesy of DLR) and is again nested in the former data set. Its resolution is about 2m. The four images are taken from an interactive application zooming from outer space into Bonn at several frames per second. The adaptive triangulations shown in the upper row contain roughly the same number of triangles (50.000-100.000) leading to a scale invariance of the rendering performance. The whole compressed data set requires less than 1 GByte for all the data residing in main memory.