
| Title | Parnass: A Cluster of Workstations |
| Participiant | Gerhard Zumbusch |
| Key words | Parallel Computing, Message Passing Interface (MPI), Parallel Virtual Machine (PVM), Distributed Memory, Myrinet, Gigabit/s High Speed Networks, local area/ system area networks (LAN/SAN), Zero-Copy Protocol |
| Description | PARNASS is a parallel computer build of single and quadruple R10k processor
Silicon Graphics workstations and servers connected by a high performance
gigabit/s speed network and additionally by switched fast ethernet.
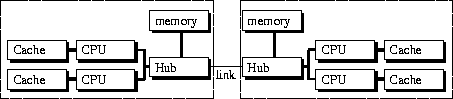
All workstations have been given the names of poets and philosophers by our system administrator. The resulting meta-computer is named after the mythological poets' place of assembly, the mountain Parnass. The similarity to the name of some parallel computing projects and companies is accidental. Parnass consists of a total of 49 (37) processors, some of them are single processors and some shared memory dual processors clustered to 4 processor shared memory machines. The single processor O2 workstation is equiped with 64 - 256 Mbytes and the dual processors Origin 200 are equiped with 192 Mbytes main memory. Each processor contains 0.5-1 Mbyte second level cache and 32+32 kbytes instruction and data first level cache.
The nodes are connected by a high performance Myrinet network at the
speed of 1.28 Gbit/s duplex. The network adapters are connected by a two
plane fat tree structure of full crossbar Myricom 8 port switches. Additionally
the nodes are connected by fast ethernet. The peak performance of Parnass
is 22.4 GFlop/s. Parnass has 4.2 Gbytes of main memory and about 150 Gbytes
of hard disk storage. Parnass is used for research on and education in
parallel and distributed computing in projects on fluid dynamcis (Navier-Stokes,
turbulence simulation), astrophysics (MHD), geology (surface flow), molecular
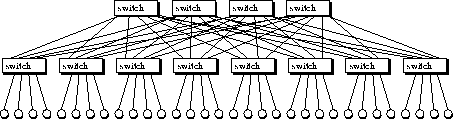
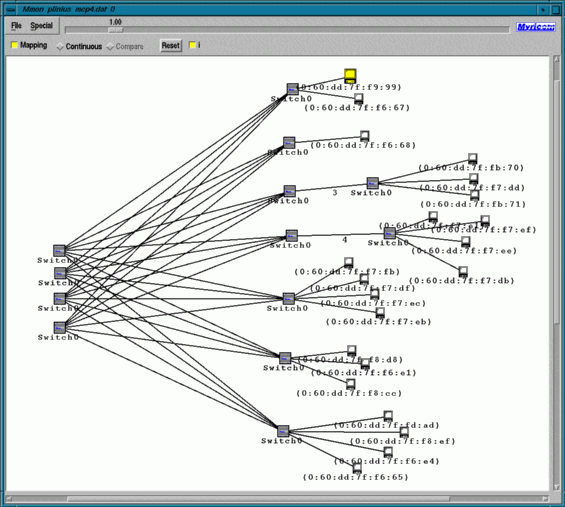
dynamics (Multipole) and parallel algorithms (multilevel). NetworkThe computing nodes are connected by three separate networks: A fast-ethernet network (nominal 100 Mbit/s) with TCP/IP connects all nodes and serves as an uplink to the internet. It is used for standard services like ftp, rsh, NFS, NIS and network graphics X11 and DGL/ openGL. Some of the nodes are connected by a common bus (nominal 10240 Mbit/s, two processor systems) or a Cray link (nominal 5760 Mbit/s) for shared memory communication (four processor systems). The third, high performance network (nominal 1280 Mbit/s) is in preparation and will be mainly used for message passing (MPI, PVM) in parallel computing between all nodes not connected via shared memory. Here both low latency and high bandwith communication are essential. In order to maintain these properties also in larger networks, the network topology plays an important role. We choose a fat-tree topology for a maximum bandwidth. Depicted is a
two stage tree built of 8-port switches. Each switch is a full-crossbar
(duplex) connection of all ports, which means a nominal switching capacity
of 10.24 Gbit/s per switch by Myricom. We show a configuration with 12
8-port switches resulting in a connection of up to 32 nodes with a backplane
of 40.96 Gbit/s total capacity. Each message has to pass either one switch
(neighbour) or exactly three switches on its way from one node to another.
This means optimal scalabilty of the network and allows collisonless all-to-all
routing. The fast-ethernet network is used for ordinary TCP/IP traffic and for the connection to other computers and terminals of the lab. The older FDDI ring connects some file servers, while the ATM uplinks the installation to the university network backbone built of ATM Oc3 components. Each fast ethernet link runs at a nominal rate of 100Mbit/s. A non-blocking crossbar ethernet switch (in preparation) has to have a backplane of at least 3.2Gbit/s. Myrinet SoftwareWe are interested in using the Myrinet on Parnass. In order to do message passing over a Myrinet on MIPS based machines, we have to port an operating system kernel driver, a control program for the NIC, and a message passing application interface for the user program. Such components are available in source code for Linux PCs and for Suns, some even for Power PCs and Windows NT on Intel and DEC Alpha based machines. However, no such drivers had been written for Silicon Graphics workstations so far. The data flow is depicted in the next figure. The memory copy operations
by the host CPU of the original driver software are substituted by the
faster DMA operations by the NIC. We implement a zero-copy protocol.
ComparisonWe compare the performance of all MPI implementations available on Parnass,
vased on the portable MPICH implementation. We use a ping-pong test to
measure latencies and performance between single processor workstations.
The shared memory tests were run on a quadruple processor Origin 200.
pink line: MPI using the shared memory
device on a multiprocessor machine. The ping-pong one-way latencies vary from 16 us for shared memory, 70
us for BullFrog on Myrinet to 0.63 ms for Fast Ethernet and 1.15 ms for
Ethernet. The peak bandwidth performance is 7 Mbit/s for Ethernet, 40-47
Mbit/s for Fast Ethernet, up to 220 Mbit/s for Myrinet and 1 Gbit/s for
shared memory. The high latencies of Ethernet are in part due to the TCP/IP
overhead involved. Fast Ethernet compared to Ethernet starts paying off
for packets longer than 1.5 kbytes. While it is a factor of 2 faster for
small messages, the peak bandwidth is 6-7 times higher than Ethernet.
The latencies for the shared memory device mainly demonstrate OS and
MPI administration overhead and time for system calls. The peak bandwidth
is limited by some `memcopy' operations through shared memory. Bandwidth
even decreases for packets larger than the size of the 2nd level cache
down to 610 Mbit/s. The theoretical peak bandwidth of the shared memory
connection between two double processor boards (CrayLink) is 5.76 Gbit/s
and the on board connection is even faster. A gap between the performance of shared memory communication and performance
of the Myrinet communication could be observed, the first one available
only between a few processors and the latter one available between all
processors. However, one has to keep in mind that the Myrinet network performance
scales better than shared memory links. This is also true for higher numbers
of processor if we compare the Origin 2000 network fabric with Myrinet.
Furthermore, workstations equiped with Myrinet posses a much more attractive
price/ performance ratio than large shared memory machines. |
| Bibliography |
|
| Related projects |
|
| In cooperation with |
|


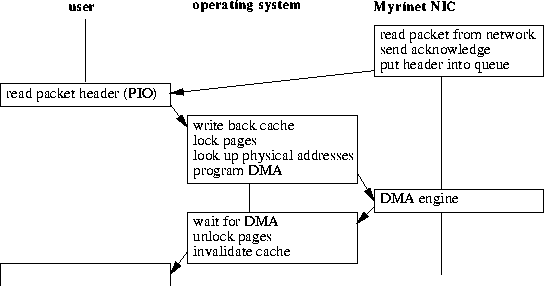
 At the time the destination address
is known, the DMA transfer can be initiated. On single processor O2 machines
this requires a cache invalidate call for the destination region (on the
sender a cache write-back). The destination address usually does not point
into physically contiguous memory. The memory is contiguous from the users
view, which is done by the processors memory management unit (MMU). However,
the memory block looks fragmented from the point of view of an I/O device.
Hence the block has to be split into memory pages, whose addresses have
to be translated. This gives a list of addresses and lengths, which can
be programmed into the DMA unit of the NIC. Fortunately, we do not need
an NIC processor interaction. Register access is sufficient. Before we
are allowed to initiate the DMA, we have to lock the pages in memory to
avoid paging. This also means that we have to wait for the DMA to terminate
to unlock the pages and to return to the user context. The DMA operation
becomes blocking.
At the time the destination address
is known, the DMA transfer can be initiated. On single processor O2 machines
this requires a cache invalidate call for the destination region (on the
sender a cache write-back). The destination address usually does not point
into physically contiguous memory. The memory is contiguous from the users
view, which is done by the processors memory management unit (MMU). However,
the memory block looks fragmented from the point of view of an I/O device.
Hence the block has to be split into memory pages, whose addresses have
to be translated. This gives a list of addresses and lengths, which can
be programmed into the DMA unit of the NIC. Fortunately, we do not need
an NIC processor interaction. Register access is sufficient. Before we
are allowed to initiate the DMA, we have to lock the pages in memory to
avoid paging. This also means that we have to wait for the DMA to terminate
to unlock the pages and to return to the user context. The DMA operation
becomes blocking.